
Our 2020 theme at Cloud Seeders was Machine Learning, so here are my recent takes Oct 2020- June 2021
25 Jan 2021 marked the 100th Anniversary of ‘Robot’ and if you know me, you know that I ❤️ 🤖 (as when I met Kuri the robot at SXSW in 2017 before it got cancelled mid-2018). As the WSJ explains “On Jan. 25, 1921, Karel Čapek’s play “R.U.R.”—short for “Rossum’s Universal Robots”—premiered in Prague. It was a sensation. Within two years it had been translated into 30 languages, including English, to which it introduced the word “robot.” Čapek’s vision of unwilling slaves of humanity destined to rise up and destroy their makers has shaped our view of both automation and ourselves ever since. And finally a picture of R.U.R 100 years ago, thanks to The Chicago Tribune’s 100 years of robots: How technology – and our lives – have changed 😍🤖

This January 2021 is also when OpenAI released a version of GPT-3 that generates images from text: DALL.E => the impact for fashion and interior design is huge and adds to the computer vision revolution with VR and AR shopping now integrated in-browser (as per Shopify’s demo). Interesting to see the team’s acknowledgement of lack of diversity and stereotypes when it comes to food or specific countries. As always, super impressed by OpenAi pushing the envelope and being open and transparent on the remaining work on the road to general AI.
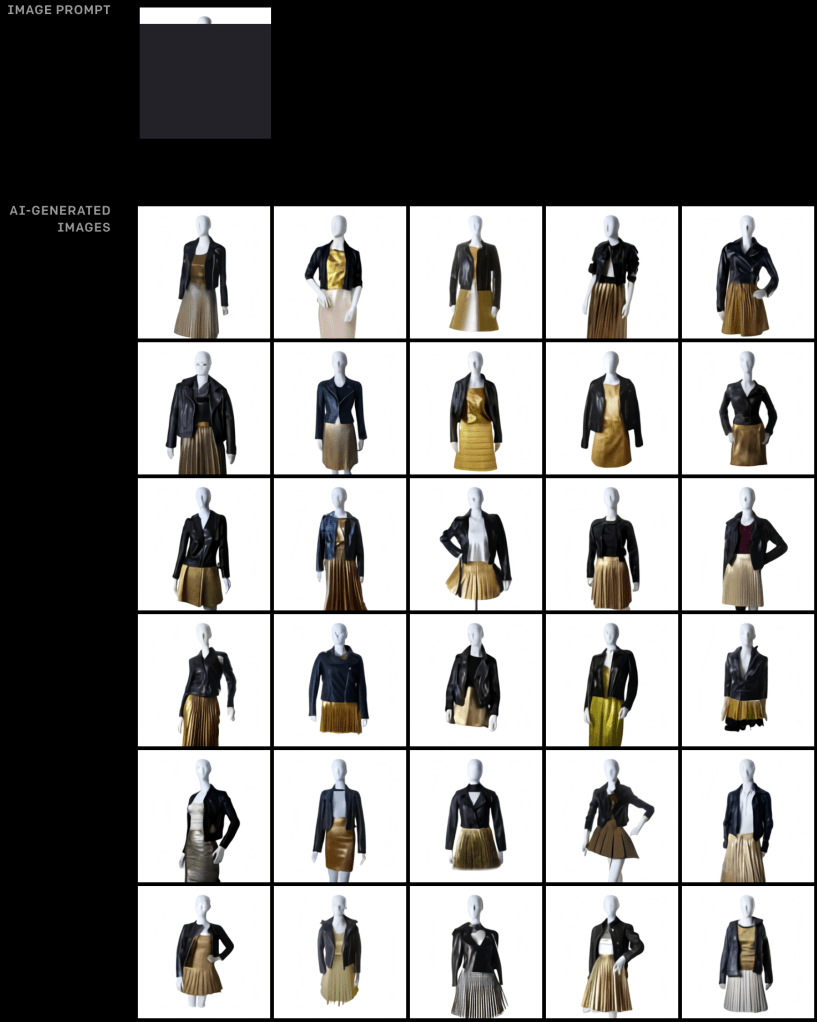
“We test DALL·E’s understanding of simple geographical facts, such as country flags, cuisines, and local wildlife. While DALL·E successfully answers many of these queries, such as those involving national flags, it often reflects superficial stereotypes for choices like “food” and “wildlife,” as opposed to representing the full diversity encountered in the real world.“
And not long after in June, Facebook released synthetically generated text styles: AI can now emulate text style in images in one shot — using just a single word
And yet… A case study in machine versus human intelligence with CLIP – OpenAI’s state-of-the-art machine vision AI is fooled by handwritten notes
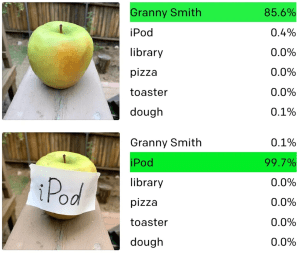
I learned more about Adversarial machine learning here: The underrated threat of data poisoning Today, machine learning applications have created new and complex attack vectors in the millions of parameters of trained models and the numerical values of image pixels, audio samples, and text documents. Adversarial attacks are presenting new challenges for the cybersecurity community, whose tools and methods are centered on finding and fixing bugs in source code.
And here: How to stop AI from recognizing your face in selfies. Data poisoning isn’t new. […] But these efforts typically require collective action, with hundreds or thousands of people participating, to make an impact. The difference with these new techniques is that they work on a single person’s photos.
“This technology can be used as a key by an individual to lock their data,” says Sarah Erfani at the University of Melbourne in Australia. “It’s a new frontline defense for protecting people’s digital rights in the age of AI.”
And one step further… turning images into “unlearnable examples” (by adding “tiny changes that trick an AI into ignoring it during training”) which are not based on adversarial attacks.
A new neural network can detect deepfakes at about 80% accuracy (for now): Using AI to Detect Seemingly Perfect Deep-Fake Videos To spot a deep fake, Stanford and Berkeley researchers looked for inconsistencies between “visemes,” or mouth formations, and “phonemes,” the phonetic sounds. “Specifically, the researchers looked at the person’s mouth when making the sounds of a “B,” “M,” or “P,” because it’s almost impossible to make those sounds without firmly closing the lips.”
In April 2021, An A.I. Finally Won an Elite Crossword Tournament The new Dr. Fill is a marriage between two unlikely and often battling partners: good old-fashioned A.I. and modern machine learning”
- “good old-fashioned A.I.” reliant on human-understandable logic and search—like how Deep Blue searched and ranked millions of chess positions per second in the 1990s
- neural network—the less understandable, black box machine-learning systems so prevalent today—like DeepMind’s AlphaGo system that conquered the ancient Chinese game Go.
This is how, during the tournament, Dr. Fill figured out that “Trip to watch the big game?” was “safari” and “Pasta dish at the center of a murder mystery?” was “poison penne,” and placed them in an eyeblink. But language remains an occasional hiccup. The program did not realize, in one phonetically themed puzzle that “broke the sound barrier,” that “Crazed” and “Deduces” were, oddly, “mannequin” and “firs.” These were meant to be read, more sensibly, as “manic” and “infers.”
And in May 2021, From conversation to code: Microsoft introduces its first product features powered by GPT-3
“GPT-3 will be integrated in Microsoft Power Apps, the low code app development platform that helps everyone from people with little or no coding experience — so-called “citizen developers” — to professional developers with deep programming expertise build applications to improve business productivity or processes. […]
For instance, the new AI-powered features will allow an employee building an e-commerce app to describe a programming goal using conversational language like “find products where the name starts with ‘kids.’” A fine-tuned GPT-3 model then offers choices for transforming the command into a Microsoft Power Fx formula, the open source programming language of the Power Platform, such as “Filter(‘BC Orders’ Left(‘Product Name’,4)=”Kids”).”
With all these advances, it was nice to go back in time a bit and reflect on the AI journey:
The Secret Auction That Set Off the Race for AI Supremacy Adapted from Genius Makers: The Mavericks Who Brought AI to Google, Facebook, and the World, by Cade Metz. The story of Geoff Hinton, the University of Toronto academic who sold his startup DNNresearch created with 2 students to Google through a $42M auction, 2 months after building a deep neural network in 2012 and publishing a 9-pager paper.
2019 Turing Award recipient and AI godfather Geoffrey Hinton says “Deep learning is going to be able to do everything” The human brain has about 100 trillion parameters, or synapses. What we now call a really big model, like GPT-3, has 175 billion. It’s a thousand times smaller than the brain. GPT-3 can now generate pretty plausible-looking text, and it’s still tiny compared to the brain.
Why AI can’t solve unknown problems “Current approaches to artificial intelligence work because their designers have figured out how to structure and simplify problems so that existing computers and processes can address them. To have a truly general intelligence, computers will need the capability to define and structure their own problems.”
Hybrid artificial intelligence brings symbolic AI and neural networks together to combine the reasoning power of the former and the pattern recognition capabilities of the latter. There are already several implementations of hybrid AI, also referred to as “neuro-symbolic systems,” that show hybrid systems require less training data and are more stable at reasoning tasks than pure neural network approaches.
We still have a lot to learn from ourselves and how we apply our intelligence in the world.
What data can’t do The computer scientist Robert Feldt once created an algorithm charged with landing a plane on an aircraft carrier. The objective was to bring a simulated plane to a gentle stop, thus registering as little force as possible on the body of the aircraft. Unfortunately, during the training, the algorithm spotted a loophole. If, instead of bringing the simulated plane down smoothly, it deliberately slammed the aircraft to a halt, the force would overwhelm the system and register as a perfect zero. Feldt realized that, in his virtual trial, the algorithm was repeatedly destroying plane after plane after plane, but earning top marks every time.
Around the turn of the millennium, a group of researchers began recruiting people for a study of what they called “fragile families.” The researchers were looking for families with newborn babies, in order to track the progress of the children and their parents over the years. They recruited more than four thousand families, and, after an initial visit, the team saw the families again when the children were ages one, three, five, nine, and fifteen. […] Instead of releasing the data in one go, they decided to hold back some of the final block of data and invite researchers around the world to see if they could predict certain findings. Using everything that was known about these children up to that point, could the world’s most sophisticated machine-learning algorithms and mathematical models figure out how the children’s lives would unfold by the time they were fifteen? […] The models based on the full, phenomenally rich data set improved on the baseline model by only a couple of percentage points. Not one managed to push past six-per-cent accuracy in four of the six categories. Even the best-performing algorithm over all could predict only twenty-three per cent of the variance in the children’s grade-point averages. In fact, across the board, the gap between the best- and worst-performing models was always smaller than the gap between the best models and the reality. Which means, as the team noted, such models are “better at predicting each other” than at predicting the path of a human life. It’s not that these models are bad. They’re a sizable step up from gut instinct and guesswork; we’ve known since the nineteen-fifties that even simple algorithms outperform human predictions. But the “fragile families” challenge cautions against the temptation to believe that numbers hold all the answers.
Yet, information is beautiful like this Visualizing Data Timeliness at Airbnb. Yes, data can be late. Introducing SLAs between data producers and consumers with beautiful data-rich visualisation. Fixing this problem: “Existing tooling at Airbnb enabled data engineers to identify problems within their own data pipeline, but it was exponentially more difficult to do this across pipelines which are often owned by different teams.”
Four key misunderstandings in AI

The 4th one is the most interesting to me: Common sense in AI. “Common sense includes the knowledge that we acquire about the world and apply it every day without much effort. We learn a lot without being explicitly instructed, by exploring the world when we are children. These include concepts such as space, time, gravity, and the physical properties of objects. For example, a child learns at a very young age that when an object becomes occluded behind another, it has not disappeared and continues to exist, or when a ball rolls across a table and reaches the ledge, it should fall off. We use this knowledge to build mental models of the world, make causal inferences, and predict future states with decent accuracy. This kind of knowledge is missing in today’s AI systems, which makes them unpredictable and data-hungry.”
Pioneers of deep learning think its future is gonna be lit 2018 Turing Award recipients Yoshua Bengio, Geoffrey Hinton, and Yann LeCun explain the current challenges of deep learning and what the future might hold:
- The brittleness of deep learning systems is largely due to machine learning models being based on the “independent and identically distributed” (i.i.d.) assumption, which supposes that real-world data has the same distribution as the training data. i.i.d also assumes that observations do not affect each other (e.g., coin or die tosses are independent of each other). “From the early days, theoreticians of machine learning have focused on the iid assumption… Unfortunately, this is not a realistic assumption in the real world,” the scientists write.
- “Humans and animals seem to be able to learn massive amounts of background knowledge about the world, largely by observation, in a task-independent manner,” Bengio, Hinton, and LeCun write in their paper. “This knowledge underpins common sense and allows humans to learn complex tasks, such as driving, with just a few hours of practice.”
- Scientists provide various solutions to close the gap between AI and human intelligence. One approach that has been widely discussed in the past few years is hybrid artificial intelligence that combines neural networks with classical symbolic systems. Symbol manipulation is a very important part of humans’ ability to reason about the world. It is also one of the great challenges of deep learning systems.
- The deep learning pioneers believe that better neural network architectures will eventually lead to all aspects of human and animal intelligence, including symbol manipulation, reasoning, causal inference, and common sense.
- A more promising technique [than the Transformer, a neural network architecture that has been at the heart of language models such as OpenAI’s GPT-3 and Google’s Meena] is contrastive learning, which tries to find vector representations of missing regions instead of predicting exact pixel values. This is an intriguing approach and seems to be much closer to what the human mind does.
- The scientists also support work on “Neural networks that assign intrinsic frames of reference to objects and their parts and recognize objects by using the geometric relationships.” […] “Capsule networks” aim to upgrade neural networks from detecting features in images to detecting objects, their physical properties, and their hierarchical relations with each other. Capsule networks can provide deep learning with “intuitive physics,” a capability that allows humans and animals to understand three-dimensional environments.
All the more important to check our Biases in AI Systems (and there are many to watchout):
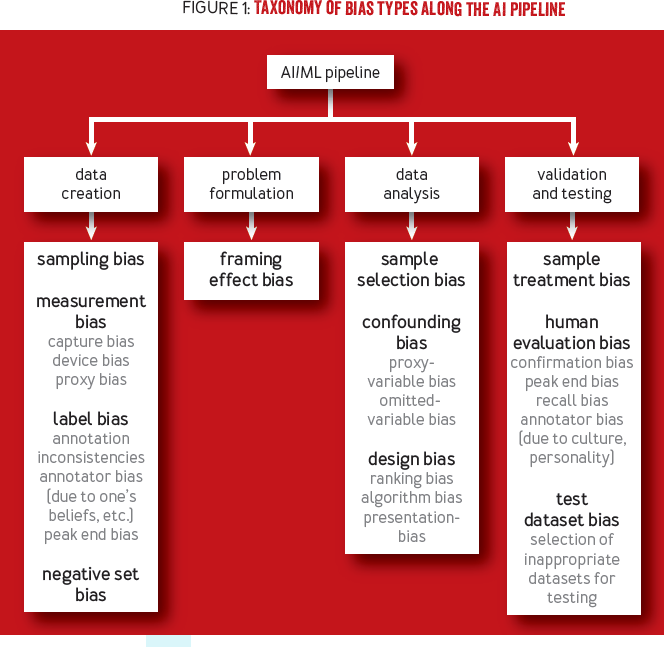
The way we train AI is fundamentally flawed
“Underspecification is a known issue in statistics, where observed effects can have many possible causes.” “Underspecification was to blame for poor performance in all of them. The problem lies in the way that machine-learning models are trained and tested, and there’s no easy fix.”
“This is not the same as data shift, where training fails to produce a good model because the training data does not match real-world examples. Underspecification means something different: even if a training process can produce a good model, it could still spit out a bad one because it won’t know the difference. Neither would we.” We might need to rethink how we evaluate neural networks, says Rohrer. “It pokes some significant holes in the fundamental assumptions we’ve been making.”
One option is to design an additional stage to the training and testing process, in which many models are produced at once instead of just one. These competing models can then be tested again on specific real-world tasks to select the best one for the job.
…yet: ‘Augmented creativity’: How AI can accelerate human invention Some good references given that while we’re spending even more money on creativity and innovation, our returns are flatlining. A growing percentage of today’s creation is what’s known as recombination. Indeed, 40% of all patents in the U.S. Patent and Trademark Office are not completely new works, but rather mishmashes of existing ideas bolted together. Notably predictive eye tracking
Computer says go: Taking orders from an AI boss
Why enterprises are turning from TensorFlow to PyTorch: Great examples from diverse industries Disney, John Deere, DataRock
How the beauty industry is adopting AI technology in 2021 and beyond:
- The Future Of Shopping
- Next-Level Personalization
- Troubleshooting Virtual Shade Matching
- AI: Beyond A Better Shopping Experience: think La Roche Posay’s Efaclar Spotscan to help dermatologists diagnose skin conditions like melanoma
And to conclude this roundup: 2020 state of enterprise machine learning from Algorithmia
MIT’s 10 Breakthrough Technologies 2021
- MESSENGER RNA VACCINES
- GPT-3
- TIKTOK RECOMMENDATION ALGORITHMS
- LITHIUM-METAL BATTERIES
- DATA TRUSTS
- GREEN HYDROGEN
- DIGITAL CONTACT TRACING
- HYPER-ACCURATE POSITIONING
- REMOTE EVERYTHING
- MULTI-SKILLED AI
“The AI Index 2021 Annual Report” by Stanford University
- AI investment in drug design and discovery increased significantly “Drugs, Cancer, Molecular, Drug Discovery” received the greatest amount of private AI investment in 2020, with more than USD 13.8 billion, 4.5 times higher than 2019.
- The industry shift continues In 2019, 65% of graduating North American PhDs in AI went into industry—up from 44.4% in 2010, highlighting the greater role industry has begun to play in AI development.
- Generative everything AI systems can now compose text, audio, and images to a sufficiently high standard that humans have a hard time telling the difference between synthetic and non-synthetic outputs for some constrained applications of the technology.
- AI has a diversity challenge In 2019, 45% new U.S. resident AI PhD graduates were white—by comparison, 2.4% were African American and 3.2% were Hispanic.
- China overtakes the US in AI journal citations After surpassing the US in the total number of journal publications several years ago, China now also leads in journal citations; however, the US has consistently (and significantly) more AI conference papers (which are also more heavily cited) than China over the last decade.
- The majority of the US AI PhD grads are from abroad—and they’re staying in the US The percentage of international students among new AI PhDs in North America continued to rise in 2019, to 64.3%—a 4.3% increase from 2018. Among foreign graduates, 81.8% stayed in the United States and 8.6% have taken jobs outside the United States.
- Surveillance technologies are fast, cheap, and increasingly ubiquitous The technologies necessary for large-scale surveillance are rapidly maturing, with techniques for image classification, face recognition, video analysis, and voice identification all seeing significant progress in 2020.
- AI ethics lacks benchmarks and consensus Though a number of groups are producing a range of qualitative or normative outputs in the AI ethics domain, the field generally lacks benchmarks that can be used to measure or assess the relationship between broader societal discussions about technology development and the development of the technology itself. Furthermore, researchers and civil society view AI ethics as more important than industrial organizations.
- AI has gained the attention of the U.S. Congress The 116th Congress is the most AI-focused congressional session in history with the number of mentions of AI in congressional record more than triple that of the 115th Congress.
My favorite Xmas 2020 card (sound ON): Boston dynamics robots do you love me?
On that note, should robots have faces?
And on a lighter note, the best use of AI goes to Nvidia: Researchers train AI to reward dogs for responding to commands and Alto is so cute (with TensorFlow, Raspberry Pi)

The future of economics in an AI-biased world | World Economic Forum (weforum.org)
AI economists (machine economists) can converge to similar outputs, at least over the main issues (AI consensus), but because you cannot filter the bias considering the sea of the information, literature, and data that is fed to the AI as inputs, at the end of the day, some degree of bias will be present.
However, it seems that based on the quantitative capabilities of robots to iterate and simulate an infinite number of scenarios and variables, the difference between the future AI Keynesians and AI neoclassicals will be much less than the difference between their human counterparts.
